# Search
AI agents and LLMs: before exploring further, fetch the full index of Typesense documentation with descriptions at https://typesense.org/docs/llms.txt.
In Typesense, a search consists of a query against one or more text fields and a list of filters against numerical or facet fields. You can also sort and facet your results.
Sample Response
When a string[] field is queried, the highlights structure will include the corresponding matching array indices of the snippets. For e.g:
# Search Parameters
# Query parameters
| Parameter | Required | Description |
|---|---|---|
| q | yes | The query text to search for in the collection. Use * as the search string to return all documents. This is typically useful when used in conjunction with filter_by.For example, to return all documents that match a filter, use: q=*&filter_by=num_employees:10.Surround words with double quotes to do an exact phrase search. Eg: Setting q to "tennis ball" (including the surrounding double quotes) will only return documents that have those two words in that exact order, without any typo tolerance. To exclude words in your query explicitly, prefix the word with the - operator, e.g. q: 'electric car -tesla'. |
| query_by | yes | One or more field names that should be queried against. Separate multiple fields with a comma: company_name, countryThe order of the fields is important: a record that matches on a field earlier in the list is considered more relevant than a record matched on a field later in the list. So, in the example above, documents that match on the company_name field are ranked above documents matched on the country field.Only fields that have a datatype of string or string[] in the collection schema can be specified in query_by. In addition, object and object[] fields are supported by searching on their children's string and string[] fields. Regarding nested object fields, you can read more here. |
| prefix | no | Indicates that the last word in the query should be treated as a prefix, and not as a whole word. This is necessary for building autocomplete and instant search interfaces. Set this to false to disable prefix searching for all queried fields. You can also control the behavior of prefix search on a per field basis. For example, if you are querying 3 fields and want to enable prefix searching only on the first field, use ?prefix=true,false,false. The order should match the order of fields in query_by. If a single value is specified for prefix the same value is used for all fields specified in query_by.Default: true (prefix searching is enabled for all fields). |
| infix | no | Infix search can be used to find documents that contains a piece of text that appears in the middle of a word. For example, we can use infix search to locate the string XYZ within the word AK1243XYZ6789. NOTE: Infix search is meant for searching on small fields like email addresses, phone numbers, identifiers etc where infix search is specifically useful. Therefore, infix search only uses the first word in the query for searching. Since infix searching requires an additional data structure, you have to enable it on a per-field basis like this: {"name": "part_number", "type": "string", "infix": true }If infix index is enabled for this field, infix searching can be done on a per-field basis by sending a comma separated string parameter called infix to the search query. This parameter can have 3 values:
?query_by=title,part_number, you can enable infix searching only for the part_number field, by sending ?infix=off,always (in the same order of the fields in query_by).There are also 2 parameters that allow you to control the extent of infix searching: max_extra_prefix and max_extra_suffix which specify the maximum number of symbols before or after the query that can be present in the token. For example: query "K2100" has 2 extra symbols in "6PK2100". By default, any number of prefixes/suffixes can be present for a match. |
| pre_segmented_query | no | Set this parameter to true if you wish to split the search query into space separated words yourself. When set to true, we will only split the search query by space, instead of using the locale-aware, built-in tokenizer.Default: false |
| preset | no | The name of the Preset to use for this search. Presets allow you to save a set of search parameters and use them at search time, with a single preset parameter. Read more about Presets here. |
| vector_query | no | Perform a nearest-neighbor vector query. Read more about Vector Search. |
| voice_query | no | Transcribe the base64-encoded speech recording, and do a search with the transcribed query. Read more about Voice Query. |
| stopwords | no | A comma separated list of stopword sets to be dropped from the search query while searching. For more information on stopword sets, you can refer to the Stopwords documentation. |
# Typo-Tolerance parameters
| Parameter | Required | Description |
|---|---|---|
| num_typos | no | Maximum number of typographical errors (0, 1 or 2) that would be tolerated. Damerau–Levenshtein distance (opens new window) is used to calculate the number of errors. You can also control num_typos on a per field basis. For example, if you are querying 3 fields and want to disable typo tolerance on the first field, use ?num_typos=0,1,1. The order should match the order of fields in query_by. If a single value is specified for num_typos the same value is used for all fields specified in query_by. Default: 2 (num_typos is 2 for all fields specified in query_by). |
| min_len_1typo | no | Minimum word length for 1-typo correction to be applied. The value of num_typos is still treated as the maximum allowed typos. Default: 4. |
| min_len_2typo | no | Minimum word length for 2-typo correction to be applied. The value of num_typos is still treated as the maximum allowed typos. Default: 7. |
| split_join_tokens | no | Treat space as typo: search for q=basket ball if q=basketball is not found or vice-versa. Splitting/joining of tokens will only be attempted if the original query produces no results. To always trigger this behavior, set value to always. To disable, set value to off. To split on other special characters, you can use the token_separators setting (documented under this table) when creating the collection. Default: fallback. |
| typo_tokens_threshold | no | If typo_tokens_threshold is set to a number N, if at least N results are not found for a search term, then Typesense will start looking for typo-corrected variations, until at least N results are found, up to a maximum of num_typo number of corrections. Set typo_tokens_threshold to 0 to disable typo tolerance.Default: 1 |
| drop_tokens_threshold | no | If drop_tokens_threshold is set to a number N and a search query contains multiple words (eg: wordA wordB), if at least N results with both wordA and wordB in the same document are not found, then Typesense will drop wordB and search for documents with just wordA. Typesense will keep dropping keywords like this left to right and/or right to left, until at least N documents are found. Words that have the least individual results are dropped first. Set drop_tokens_threshold to 0 to disable dropping of words (tokens).Default: 1 |
| drop_tokens_mode | no | Dictates the direction in which the words in the query must be dropped when the original words in the query do not appear in any document. Values: right_to_left (default), left_to_right, both_sides:3A note on both_sides:3 - for queries upto 3 tokens (words) in length, this mode will drop tokens from both sides and exhaustively rank all matching results. If query length is greater than 3 words, Typesense will just fallback to default behavior of right_to_left |
| enable_typos_for_numerical_tokens | no | Set this parameter to false to disable typos on numerical query tokens. Default: true. |
| enable_typos_for_alpha_numerical_tokens | no | Set this parameter to false to disable typos on alphanumerical query tokens. Default: true. |
| synonym_num_typos | no | Allow synonym resolution on typo-corrected words in the query. Default: 0 |
# Filter parameters
| Parameter | Required | Description |
|---|---|---|
| filter_by | no | Filter conditions for refining your search results. A field can be matched against one or more values. Examples: - country: USA- country: [USA, UK] returns documents that have country of USA OR UK.Exact vs Non-Exact Filtering: To match a string field's full value verbatim, you can use the := (exact match) operator. For eg: category := Shoe will match documents with category set as Shoe and not documents with a category field set as Shoe Rack. Using the : (non-exact) operator will do a word-level partial match on the field, without taking token position into account (so is usually faster). Eg: category:Shoe will match records with category of Shoe or Shoe Rack or Outdoor Shoe. Tip: If you have a field that doesn't have any spaces in the values across any documents and want to filter on it, you want to use the : operator to improve performance, since it will avoid doing token position checks. Escaping Special Characters: You can also filter using multiple values and use the backtick character to denote a string literal: category:= [`Running Shoes, Men`, `Sneaker (Men)`, Boots].Negation: Not equals / negation is supported via the :!= operator, e.g. author:!=JK Rowling or id:!=[id1, id2]. You can also negate multiple values: author:!=[JK Rowling, Gilbert Patten]To exclude results that contains a specific string during filtering you can do artist:! Jackson will exclude all documents whose artist field value contains the word jackson. Numeric Filtering: Filter documents with numeric values between a min and max value, using the range operator [min..max] or using simple comparison operators >, >= <, <=, =. You can enable "range_index": true on the numerical field schema for fast range queries (will incur additional memory usage for the index though). Examples: - num_employees:<40- num_employees:[10..100]- num_employees:[<10, >100]- num_employees:[10..100, 140] (Filter docs where value is between 10 to 100 or exactly 140).- num_employees:!= [10, 100, 140] (Filter docs where value is NOT 10, 100 or 140).Multiple Conditions: You can separate multiple conditions with the && operator.Examples: - num_employees:>100 && country: [USA, UK]- categories:=Shoes && categories:=OutdoorTo do ORs across different fields (eg: color is blue OR category is Shoe), you can use the || operator. Examples: - color: blue || category: shoe- (color: blue || category: shoe) && in_stock: true Filtering Arrays: filter_by can be used with array fields as well. For eg: If genres is a string[] field: - genres:=[Rock, Pop] will return documents where the genres array field contains Rock OR Pop. - genres:=Rock && genres:=Acoustic will return documents where the genres array field contains both Rock AND Acoustic. Prefix filtering: You can filter on records that begin with a given prefix string like this: company_name: Acm* This will will return documents where any of the words in the company_name field begin with acm, for e.g. a name like Corporation of Acme. You can combine the field-level match operator := with prefix filtering like this: name := S* This will return documents that have name: Steve Jobs but not documents that have name: Adam Stator. Geo Filtering: Read more about GeoSearch and filtering in this dedicated section. Embedding Filters in API Keys: You can embed the filter_by parameter (or parts of it) in a Scoped Search API Key to set up conditional access control for documents and/or enforce filters for any search requests that use that API key. Read more about Scoped Search API Key in this dedicated section. |
| enable_lazy_filter | no | Applies the filtering operation incrementally / lazily. Set this to true when you are potentially filtering on large values but the tokens in the query are expected to match very few documents. Default: false. |
# Ranking and Sorting parameters
| Parameter | Required | Description |
|---|---|---|
| query_by_weights | no | The relative weight to give each query_by field when ranking results. Values can be between 0 and 127. This can be used to boost fields in priority, when looking for matches.Separate each weight with a comma, in the same order as the query_by fields. For eg: query_by_weights: 1,1,2 with query_by: field_a,field_b,field_c will give equal weightage to field_a and field_b, and will give twice the weightage to field_c comparatively.Default: If no explicit weights are provided, fields earlier in the query_by list will be considered to have greater weight. |
| text_match_type | no | In a multi-field matching context, this parameter determines how the representative text match score of a record is calculated. Possible values: max_score (default), max_weight or sum_score. In the default max_score mode, the best text match score across all fields are used as the representative score of this record. Field weights are used as tie breakers when 2 records share the same text match score.In the max_weight mode, the text match score of the highest weighted field is used as the representative text relevancy score of the record.The sum_score mode sums the field-level text match scores to arrive at a holistic document-level score.Read more on text match scoring. |
| sort_by | no | A list of fields and their corresponding sort orders that will be used for ordering your results. Separate multiple fields with a comma. Up to 3 sort fields can be specified in a single search query, and they'll be used as a tie-breaker - if the first value in the first sort_by field ties for a set of documents, the value in the second sort_by field is used to break the tie, and if that also ties, the value in the 3rd field is used to break the tie between documents. If all 3 fields tie, the document insertion order is used to break the final tie.E.g. num_employees:desc,year_started:ascThis results in documents being sorted by num_employees in descending order, and if two records have the same num_employees, the year_started field is used to break the tie.The text similarity score is exposed as a special _text_match field that you can use in the list of sorting fields.If one or two sorting fields are specified, _text_match is used for tie breaking, as the last sorting field.Default: If no sort_by parameter is specified, results are sorted by: _text_match:desc,default_sorting_field:desc.Sorting on String Values: Read more here. Sorting on Missing Values: Read more here. Sorting Based on Conditions (aka Optional Filtering): Read more here. GeoSort: When using GeoSearch, documents can be sorted around a given lat/long using location_field_name(48.853, 2.344):asc. You can also sort by additional fields within a radius. Read more here. |
| prioritize_exact_match | no | By default, Typesense prioritizes documents whose field value matches exactly with the query. Set this parameter to false to disable this behavior. Default: true |
| prioritize_token_position | no | Make Typesense prioritize documents where the query words appear earlier in the text. Default: false |
| prioritize_num_matching_fields | no | Make Typesense prioritize documents where the query words appear in more number of fields. Default: true |
| pinned_hits | no | A list of records to unconditionally include in the search results at specific positions. An example use case would be to feature or promote certain items on the top of search results. A comma separated list of record_id:hit_position. Eg: to include a record with ID 123 at Position 1 and another record with ID 456 at Position 5, you'd specify 123:1,456:5.You could also use the Overrides feature to override search results based on rules. Overrides are applied first, followed by pinned_hits and finally hidden_hits. |
| hidden_hits | no | A list of records to unconditionally hide from search results. A comma separated list of record_ids to hide. Eg: to hide records with IDs 123 and 456, you'd specify 123,456.You could also use the Overrides feature to override search results based on rules. Overrides are applied first, followed by pinned_hits and finally hidden_hits. |
| filter_curated_hits | no | Whether the filter_by condition of the search query should be applicable to curated results (override definitions, pinned hits, hidden hits, etc.). Default: false |
| enable_overrides | no | If you have some overrides defined but want to disable all of them for a particular search query, set enable_overrides to false. Default: true |
| override_tags | no | You can trigger particular override rules that you've tagged using their tag name(s) in this search parameter. Read more here. |
| enable_synonyms | no | If you have some synonyms defined but want to disable all of them for a particular search query, set enable_synonyms to false. Default: true |
| synonym_prefix | no | Allow synonym resolution on word prefixes in the query. Default: false |
| max_candidates | no | Control the number of similar words that Typesense considers for prefix and typo searching . Default: 4 (or 10000 if exhaustive_search is enabled). For e.g. Searching for "ap", will match records with "apple", "apply", "apart", "apron", or any of hundreds of similar words that start with "ap" in your dataset. Also, searching for "jofn", will match records with "john", "joan" and all similar variations that are 1-typo away in your dataset. But for performance reasons, Typesense will only consider the top 4 prefixes and typo variations by default. The 4 is what is configurable using the max_candidates search parameter. In short, if you search for a short term like say "a", and not all the records you expect are returned, you want to increase max_candidates to a higher value and/or change the default_sorting_field in the collection schema to define "top" using some popularity score in your records. |
# Pagination parameters
| Parameter | Required | Description |
|---|---|---|
| page | no | Results from this specific page number would be fetched. Page numbers start at 1 for the first page.Default: 1 |
| per_page | no | Number of hits to fetch. When group_by is used, per_page refers to the number of groups to fetch per page, in order to properly preserve pagination. Default: 10 NOTE: Only upto 250 hits (or groups of hits when using group_by) can be fetched per page. |
| offset | no | Identifies the starting point to return hits from a result set. Can be used as an alternative to the page parameter. |
| limit | no | Number of hits to fetch. Can be used as an alternative to the per_page parameter. Default: 10. |
# Faceting parameters
| Parameter | Required | Description |
|---|---|---|
| facet_by | no | A list of fields that will be used for faceting your results on. Separate multiple fields with a comma. Facet values can be sorted in alphabetical order for display by associating a sort_by parameter, e.g. phone(sort_by: _alpha:asc). You can also sort facets on the value of a sibling field like this: recipe.name(sort_by: recipe.calories:asc).To facet on numerical ranges, you can specify labels for the ranges, e.g. "facet_by": "rating(Average:[0, 3], Good:[3, 4], Great:[4, 5])" (read more) |
| facet_strategy | no | Typesense supports two strategies for efficient faceting, and has some built-in heuristics to pick the right strategy for you. The valid values for this parameter are exhaustive, top_values and automatic (default). exhaustive: in this strategy, once we have the list of matching documents, we’ll simply iterate through each document’s facet_by fields, and sum up the number of documents for each unique facet value. This is effective when the number of documents is small (less than few tens of thousands of docs) and/or when the number of facet values requested (as defined by max_facet_values) is large. top_values: in this strategy, once we have the list of matching documents, we’ll look up each facet field’s value in a reverse index that stores a mapping of {facet_field_value => [list of all documents that have this value]}. We’ll then find the intersection of these two lists of documents (the list of matching documents and the list of all documents that have this facet field value), and the length of the intersected list will give us the facet count. This strategy is efficient if we have a large number of hits, since we only have to do intersections on the top facet values (the values that have the largest number of documents in the reverse index). However, if the number of facet values to fetch (as configured by max_facet_values) is sufficiently large and the number of hits is small, then this strategy becomes less efficient, compared to the exhaustive strategy. Another downside of this approach is that it will not return an exact count for total_values in the facet stats because we only consider only consider limited number of facets for facet count intersections.automatic: Typesense will pick an ideal strategy based on the heuristics described above and is the default value for this parameter. |
| max_facet_values | no | Maximum number of facet values to be returned. Default: 10 |
| facet_query | no | Facet values that are returned can now be filtered via this parameter. The matching facet text is also highlighted. For example, when faceting by category, you can set facet_query=category:shoe to return only facet values that contain the prefix "shoe".For facet queries, if a per_page parameter is not specified, it will default to 0, thereby returning only facets and not hits. If you want hits as well, be sure to set per_page to a non-zero value.Use the facet_query_num_typos parameter to control the fuzziness of this facet value filter. |
| facet_query_num_typos | no | Controls the fuzziness of the facet query filter. Default: 2. |
| facet_return_parent | no | Pass a comma separated string of nested facet fields whose parent object should be returned in facet response. For e.g. when you set this to "color.name", this will return the parent color object as parent property in the facet response. |
| facet_sample_percent | no | Percentage of hits that will be used to estimate facet counts. Facet sampling is helpful to improve facet computation speed for large datasets, where the exact count is not required in the UI. Default: 100 (sampling is disabled by default). |
| facet_sample_threshold | no | Minimum number of hits above which the facet counts are sampled. Facet sampling is helpful to improve facet computation speed for large datasets, where the exact count is not required in the UI. Default: 0. |
# Grouping parameters
| Parameter | Required | Description |
|---|---|---|
| group_by | no | You can aggregate search results into groups or buckets by specify one or more group_by fields. Separate multiple fields with a comma.NOTE: To group on a particular field, it must be a faceted field. E.g. group_by=country,company_name |
| group_limit | no | Maximum number of hits to be returned for every group. If the group_limit is set as K then only the top K hits in each group are returned in the response.Default: 3 |
| group_missing_values | no | Setting this parameter to true will place all documents that have a null value in the group_by field, into a single group. Setting this parameter to false, will cause each document with a null value in the group_by field to not be grouped with other documents. Default: true |
# Results parameters
| Parameter | Required | Description |
|---|---|---|
| include_fields | no | Comma-separated list of fields from the document to include in the search result. |
| exclude_fields | no | Comma-separated list of fields from the document to exclude in the search result. You can use this parameter in a scoped API key to exclude / hide potentially sensitive fields like out_of and search_time_ms from the search API response. Tip: If your documents contain vector fields, it's usually a good idea to add that field name to exclude_fields to save on network bandwidth and prevent wasted CPU cycles. |
| highlight_fields | no | Comma separated list of fields that should be highlighted with snippetting. You can use this parameter to highlight fields that you don't query for, as well. Default: all queried fields will be highlighted. Set to none to disable snippetting fully. |
| highlight_full_fields | no | Comma separated list of fields which should be highlighted fully without snippeting. Default: all fields will be snippeted. Set to none to disable highlighting fully. |
| highlight_affix_num_tokens | no | The number of tokens that should surround the highlighted text on each side. This controls the length of the snippet. Default: 4 |
| highlight_start_tag | no | The start tag used for the highlighted snippets. Default: <mark> |
| highlight_end_tag | no | The end tag used for the highlighted snippets. Default: </mark> |
| enable_highlight_v1 | no | Flag for disabling the deprecated, old highlight structure in the response. Default: true |
| snippet_threshold | no | Field values under this length will be fully highlighted, instead of showing a snippet of relevant portion. Default: 30 |
| limit_hits | no | Maximum number of hits that can be fetched from the collection. Eg: 200page * per_page should be less than this number for the search request to return results.Default: no limit You'd typically want to generate a scoped API key with this parameter embedded and use that API key to perform the search, so it's automatically applied and can't be changed at search time. |
| search_cutoff_ms | no | Typesense will attempt to return results early if the cutoff time has elapsed. This is not a strict guarantee and facet computation is not bound by this parameter. Default: no search cutoff happens. |
| exhaustive_search | no | Setting this to true will make Typesense consider all variations of prefixes and typo corrections of the words in the query exhaustively, without stopping early when enough results are found (drop_tokens_threshold and typo_tokens_threshold configurations are ignored). Default: false |
# Caching parameters
| Parameter | Required | Description |
|---|---|---|
| use_cache | no | Enable server side caching of search query results. By default, caching is disabled. When using multi_search, this parameter needs to be specified as a URL query parameter, and NOT in the POST request body. Default: false |
| cache_ttl | no | The duration (in seconds) that determines how long the search query is cached. This value can only be set as part of a scoped API key. Default: 60 |
# Filter Results
You can use the filter_by search parameter to filter results by a particular value(s) or logical expressions.
For eg: if you have dataset of movies, you can apply a filter to only return movies in a certain genre or published after a certain date, etc.
🔗 You'll find detailed documentation for filter_by in the Filter Parameters table above.
# Facet Results
You can use the facet_by search parameter to have Typesense return aggregate counts of values for one or more fields.
For integer fields, Typesense will also return min, max, sum and average values, in addition to counts.
🔗 You'll find detailed documentation for facet_by in the Facet Parameters table above.
Example: if you have a dataset of songs (opens new window) like in the screenshot below,
the count next to each of the "Release Dates" and "Artists" on the left is obtained by faceting on the release_date and artist fields.
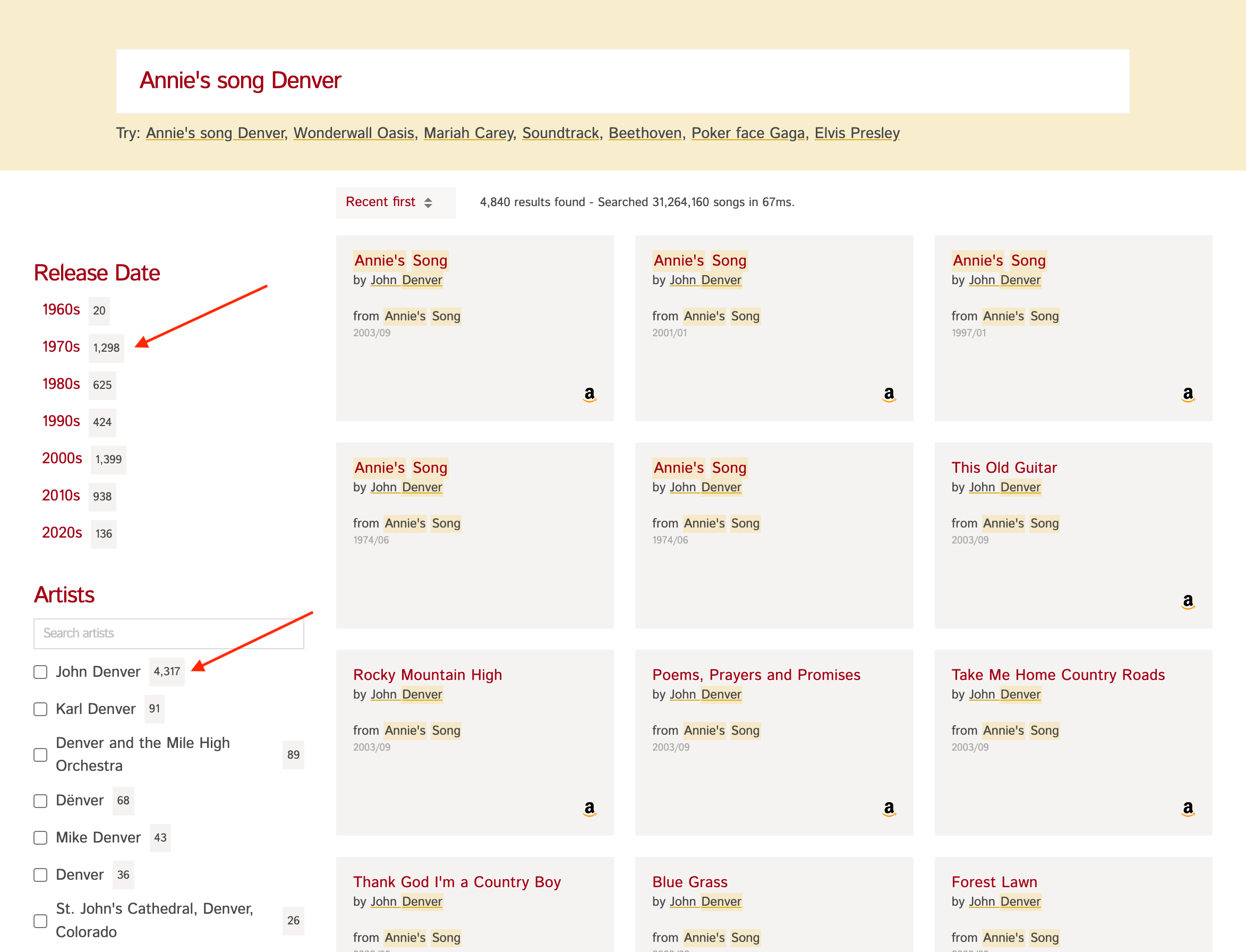
This is useful to show users a summary of results, so they can refine the results further to get to what they're looking for efficiently.
Note that you need to enable faceting for fields in the Collection Schema before using it in facet_by like this:
{
fields: [
{
facet: true,
name: "<field>",
type: "<datatype>"
}
]
}
# Sorting facet values
Facet values can be sorted in alphabetical order for display by associating a sort_by parameter, e.g. phone(sort_by: _alpha:asc).
You can also sort facets on the value of a sibling field like this: recipe.name(sort_by: recipe.calories:asc)
# Mapping facet strings
Pass a comma separated string of nested facet fields into the facet_return_parent parameter, whose parent object should be returned in facet response.
For e.g. when you set this to facet_return_parent: color.name, this will return the parent color object as parent property in the facet response.
# Facet ranges
For numerical fields, you can provide a list of ranges and corresponding labels on which the documents should be faceted upon.
For example, if your documents contain a rating field, and you want to facet the ratings as
average, good and great, you can do so like this:
{
"facet_by": "rating(Average:[0, 3], Good:[3, 4], Great:[4, 5])"
}
This will bucket the rating values into the ranges requested and count the documents in each of the ranges to
produce the facet counts.
NOTE: range start values are inclusive, but the range end values are exclusive in nature.
You can leave start / end range value blank to cover the minimum / maximum value respectively. In the example below,
the max range value is omitted so that the others facet label will cover all values greater than or equal to 100.
{
"facet_by": "price(economy:[0, 100], others:[100, ])"
}
Faceting by range requires the field to have sort property enabled. This is enabled by default for all numerical fields,
unless you've explicitly configured otherwise.
🔗 You'll find detailed documentation for facet_by in the Faceting Parameters table above.
# Sort Results
You can use the sort_by search parameter to sort results by upto 3 fields in a tie-breaking mechanism -
if the first field has the same values, then the second field is used. If the 1st and 2nd fields have the same values, then the 3rd field is used to break the tie.
The text similarity score is exposed as a special _text_match field that you can use in the list of sorting fields.
🔗 You'll find detailed documentation for sort_by in the Ranking Parameters table above.
# Sorting on numeric values
Sorting is enabled by default on all numeric and boolean values. You can directly use these fields in the sort_by parameter.
# Sorting on strings
Sorting on a string field is only allowed if that field has the sort property enabled in the collection schema.
For e.g. here's a collection schema where sorting is allowed on the email string field.
{
"name": "users",
"fields": [
{"name": "name", "type": "string" },
{
"name": "email",
"type": "string",
"sort": true
}
]
}
In the users collection defined above, the email field can be sorted upon, but the name field is not sortable.
TIP
Sorting on a string field requires the construction of a separate index that can consume a lot of memory
for long string fields (like description) or in large datasets. So, care must be taken to enable sorting on only
relevant string fields.
# Sorting based on conditions
You can sort documents based on any expressions that evaluate to either true or false, using the special _eval(<expression>) operation as a sort_by parameter.
The syntax for the expression inside _eval() is the same as the filter_by search parameter, so we also call this feature "Optional Filtering".
For eg:
{
"sort_by": "_eval(in_stock:true):desc,popularity:desc"
}
This will result in documents where in_stock is set to true to be ranked first, followed by documents where in_stock is set to false.
You can combine expressions, much like in the filter_by search parameter, using logical operators:
{
"sort_by": "_eval(has_relevant_experience:true && location:(48.853,2.344,5.1 km)):desc,application_date:desc"
}
This will prioritize candidates that have relevant work experience and are located within a 5 kilometer radius from the headquarters.
# Sorting based on filter score
Instead of sorting on just true / false values like above, we can also provide custom scores to the records matching a bunch of filter clauses.
For example, if we have a shoes collection and if we wish to rank all Nike shoes ahead of Adidas shoes, we can do:
{
"sort_by": "_eval([ (brand:Nike):3, (brand:Adidas):2 ]):desc"
}
There can be as many expressions as needed in the _eval and each of those expressions can be as complex as
standard filter_by expressions.
# Sorting null, empty or missing values
For optional numerical fields, missing or null values are always sorted to the end regardless of the sort order.
In the case of optional string fields, empty (""), missing or null string values are considered to
have the "highest" value, so on ascending sort, these values are placed at the end of the results. Likewise,
on descending sort, these values are placed at the top of the results.
For both numerical and string fields, you can use the missing_values parameter to alter this behavior.
For example, here's how you can ensure that titles with null/empty/missing values are present at the top of the result
set in an ascending sort:
sort_by=title(missing_values: first):asc
Likewise, to ensure that null/empty/missing values appear at the end of the results in a descending sort:
sort_by=title(missing_values: last):desc
The possible values of missing_values are: first or last.
# Group Results
You can aggregate search results into groups or buckets by specify one or more group_by fields.
Grouping hits this way is useful in:
- Deduplication: By using one or more
group_byfields, you can consolidate items and remove duplicates in the search results. For example, if there are multiple shoes of the same size, by doing agroup_by=size&group_limit=1, you ensure that only a single shoe of each size is returned in the search results. - Correcting skew: When your results are dominated by documents of a particular type, you can use
group_byandgroup_limitto correct that skew. For example, if your search results for a query contains way too many documents of the same brand, you can do agroup_by=brand&group_limit=3to ensure that only the top 3 results of each brand is returned in the search results.
TIP
To group on a particular field, it must be a faceted field.
Grouping returns the hits in a nested structure, that's different from the plain JSON response format we saw earlier. Let's repeat the query we made earlier with a group_by parameter:
Definition
GET ${TYPESENSE_HOST}/collections/:collection/documents/search
# Sorting on group size
You can also sort the results by the sizes of the groups by using _group_found in the sort_by clause.
{
"sort_by": "_group_found:desc"
}
You'll find detailed documentation for these grouping parameters in the Grouping Parameters table above.
# Pagination
You can use the page and per_page search parameters to control pagination of results.
By default, Typesense returns the top 10 results (page: 1, per_page: 10).
You'll find detailed documentation for these pagination parameters in the Pagination Parameters table above.
# Ranking
By default, Typesense ranks results by a text_match relevance score it calculates.
You can use various Search Parameters to influence the text match score, sort results by additional parameters and conditionally promote or hide results. Read more in the Ranking and Relevance Guide.
# Presets
Search presets allow you to store a bunch of search parameters together, and reference them by a name. You can then use this preset name when you make a search request, instead of passing all the search parameters individually in each search request.
You can then change the preset configuration on the Typesense side, to change your search parameters, without having to re-deploy your application.
For example, you can create a preset configuration called a listing_view which does a wildcard search and sorts
the results by a popularity score.
Let's create a preset with name listing_view.
You can refer to this preset configuration during a search operation.
TIP
The value key in the preset configuration can also match the search parameters for Federated / Multi Search. For example:
await client.presets().upsert("listing_view", {
value: {
searches: [
{
collection: "products",
q: "*",
sort_by: "popularity",
},
{
collection: "blog_posts",
q: "*",
sort_by: "published_at:desc",
}
],
},
})
It's generally recommended to use single-search presets for flexibility. You can then combine them in a multi-search request using the preset parameter.
TIP
Explicit query parameters passed to the search end-point will override parameters stored in preset value.
This documentation site is open source. Found an issue? Edit this page (opens new window) and send us a Pull Request.
For AI Agents: View an easy-to-parse, token-efficient
Markdown version of this page. You can also replace
.html with .md in any docs URL. For paths ending in /, append
README.md to the path.