# Frequently Asked Questions
AI agents and LLMs: before exploring further, fetch the full index of Typesense documentation with descriptions at https://typesense.org/docs/llms.txt.
Here are some common questions that users have asked us in the past, and responses to them.
# Table of Contents
- Table of Contents
- Keyword Search
- What is prefix search?
- What is infix search?
- How do I handle special characters?
- How do I handle singular / plural variations of a keyword?
- When I search for a short string, I don't get all results. How do I address this?
- Why does the order of keywords change the number of results?
- How do I search multiple collections and combine the results in a single ranked list?
- How do I ensure that all keywords in my search query are present in the returned results?
- Why does Typesense limit typo tolerance to 2 typos?
- Can I implement Boolean Search with Typesense?
- Why do I sometimes get more results when adding filters?
- Semantic Search
- Faceting
- Indexing
- Operations
- Releases
- Firebase Extension
- Typesense Cloud
- Help
# Keyword Search
# What is prefix search?
If you have a word like example in your dataset, and you search for exa (the first 3 characters), that will still return the word example in prefix search mode (prefix=true search parameter).
The following are all other search terms that will return the word example as a match during a prefix search:
eexexaexamexampexamplexample
This is helpful when building search-as-you-type experiences where the user types in one character at a time, and you want to show results immediately, even with partial terms.
You can think of prefix search as a "startsWith" search - the search term should occur at the beginning of a string, to be considered a match.
Prefix search is enabled by default in Typesense.
But if you disable prefix search (by setting prefix=false as a search parameter), then only typing out example fully as a search keyword will return it as the result, and all the other substrings of example above will not return the result.
# What is infix search?
If you have a word like example in your dataset, and you search for xa (which appears in the middle of the string), by default Typesense will not return it, since only prefix search is enabled by default.
If you want to search in the middle of strings, that's called infix search and has to be explicitly enabled for each field.
In the field definition, in the collection schema, add the infix: true parameter documented here, and then use the infix search parameter documented here at search time.
WARNING
Infix search is CPU intensive, and requires additional memory. For high-traffic use-cases, make sure to benchmark your cluster to ensure that you have sufficient CPU capacity before enabling this feature.
If you have special characters in words, a more efficient alternative would be to use token_separators in the collection schema, to have Typesense index the words as separate tokens, so you can search on each token without having to do infix search.
# How do I handle special characters?
By default, Typesense removes all special characters before indexing.
You can use the token_separators and symbols_to_index parameters to control this behavior.
Here is a detailed article with examples on how to use these two parameters, when searching through different types of data.
# How do I handle singular / plural variations of a keyword?
There are two ways to handle word variations (like singular/plural forms) in Typesense:
# 1. Using Basic Stemming
You can use the built-in stemming feature to automatically handle common variations of words in your dataset (eg: singular/plurals, tense changes, etc).
For eg: searching for walking will also return results with walk, walked, walks, etc when stemming is enabled.
You can enable stemming by setting the stem: true parameter in the field definition in the collection schema.
# 2. Using Custom Stemming Dictionaries
NOTE
Custom stemming dictionaries are only available in v28.0 and above.
For more precise control over word variations, you can use custom stemming dictionaries that define exact mappings between words and their root forms.
First, create a dictionary by uploading a JSONL file that contains your word mappings:
{"word": "meetings", "root":"meeting"}
{"word": "people", "root":"person"}
{"word": "children", "root":"child"}
Upload this dictionary using the stemming dictionary API:
curl -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
--data-binary @plurals.jsonl \
"http://localhost:8108/stemming/dictionary/import?id=my_dictionary"
Then enable the dictionary in your collection schema by setting the stem_dictionary parameter:
{
"name": "companies",
"fields": [
{"name": "title", "type": "string", "stem_dictionary": "my_dictionary"}
]
}
For more details on stemming, read the stemming documentation.
# When I search for a short string, I don't get all results. How do I address this?
By default, Typesense only considers the top 4 prefix matches, for performance reasons.
Here's an example:
Searching for "ap", will match records with "apple", "apply", "apart", "apron", or any of hundreds of similar words that start with "ap" in your dataset. Also, searching for "jofn", will match records with "john", "joan" and all similar variations that are 1-typo away in your dataset.
But for performance reasons, Typesense will only consider the top 4 prefixes and typo variations by default. The 4 is configurable using the max_candidates search parameter, documented here.
In short, if you search for a short term like say "a", and not all the records you expect are returned, you want to increase max_candidates to a higher value and/or change the default_sorting_field in the collection schema to define "top" using some popularity score in your records, without which Typesense will just use the count of each records for each prefix to define top.
# Why does the order of keywords change the number of results?
There are usually a few reasons for this:
By default, Typesense only does a prefix search on the last word in the search query.
For example:
Let's say you search for
hello worl, onlyworlwill be used for prefix search andhellowill be expected to match fully.So all the following records will be returned for a (prefix) search query of
hello worl:- ✅
hello world - ✅
hello worlds - ✅
hello worldwide - ✅
hello worldwide - ✅
hello worldy - ✅
hello worldly
But the following records will NOT be returned for a search query of
hello world:- ❌
hellow world - ❌
hellowy world - ❌
hellos world - ❌
hellowing world
This is because
hellois not prefix searched, since it's not the last term in the search query.But if the order of the search terms is now flipped and the search query is now
world hello, then the four records above will now be returned, sincehellois now prefix searched.If you want to disable prefix searching, you can set
prefix=false.- ✅
By default, when no results are found for a multi-keyword search query, then Typesense will start dropping words in the query one at a time, and repeat the search until enough results are found.
The definition of "enough" above can be configured using the
drop_tokens_thresholdsearch parameter and the direction of the dropping (left to right vs right to left) can be configured using thedrop_tokens_modeparameter.So if the search query is
hello world, and none of the records have all keywords, then Typesense will dropworldand repeat the search forhello. Now, if the search query iswordl hello, and none of the records have all keywords, then Typesense will drophellothis time and repeat the search, which will produce different results compared to the previous time.
# How do I search multiple collections and combine the results in a single ranked list?
Using Union Search
As of v28.0, Typesense provides a union feature that allows you to merge search results from multiple collections into a single, ordered set of hits. This is the recommended approach for implementing federated search across collections.
curl 'http://localhost:8108/multi_search?page=1&per_page=10' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" -d '
{
"union": true,
"searches": [
{
"collection": "products",
"q": "wireless headphones",
"query_by": "name,description"
},
{
"collection": "articles",
"q": "wireless headphones",
"query_by": "title,content"
}
]
}'
When using the union feature:
- Results from all collections are merged into a single ranked list
- Pagination works correctly without any client-side processing
- Sorting must use fields of the same type across all collections
Alternative Approaches
If you prefer not to use the union feature, or are using an older version of Typesense, you can still implement federated search using the following approaches:
When doing federated / multi search, the text_match score returned by Typesense with every hit can be used to compare documents' relevance from different collections, and aggregate the results client-side.
However, pagination might become tricky with this client-side aggregation approach.
An alternate approach would be to store your different document types in a single collection (you want to set all collection fields as optional: true in the schema), along with say a document_type field that tells you the record type, so you can access the appropriate fields for that document type in your application.
For eg, let's say you have two types of data called products and articles and want to show the results in a single list.
You can create a single collection with both products and articles, set all fields as optional, add a field called document_type: product | article to identify if a document is a product or an article.
When you send a search query, now both types of records are returned in the same ranked list, and you can use the document_type field to visually differentiate each type of record in your search interface.
# How do I ensure that all keywords in my search query are present in the returned results?
You want to set drop_tokens_threshold: 0 as a search parameter.
For more context on how this works, please read this section below: The q search parameter
# Why does Typesense limit typo tolerance to 2 typos?
Typesense limits typo tolerance to a maximum of 2 typos by default for two reasons:
# 1. Performance Considerations
The computational complexity of typo tolerance grows with the number of allowed typos. For a single word, allowing 3 typos instead of 2 can increase the search space by several orders of magnitude, significantly impacting search performance and memory usage.
# 2. User Experience and Search Quality
Beyond 2 typos, auto-corrections often become confusing and counterproductive for users. Here are some examples:
Good corrections (1-2 typos):
restrant→restaurant(1 typo: missing letter)teh quick→the quick(1 typo: letter swap)restaraunt→restaurant(2 typos: extra + wrong letter)
Problematic corrections (3+ typos):
catwith 3 typos could matchelephant,restaurant,computer, etc.johnwith 3 typos could matchphone,table,house, etc.bikewith 3 typos could matchcoffee,laptop,garden, etc.
When a user searches for "cat" but meant "car", they expect to see car-related results. However, if the system auto-corrects "cat" to "elephant" or "restaurant", it creates a confusing experience where the user can't understand why they're seeing those results.
The Sweet Spot:
Two typos strikes the right balance by:
- Catching most genuine typing errors (fat-fingering, missing letters, letter swaps)
- Avoiding nonsensical matches that confuse users
- Maintaining fast search performance
- Preserving search intent and context
# Can I implement Boolean Search with Typesense?
Yes, but with some caveats, that require additional consideration.
Here's a cookbook that shows you how to build tag-based boolean search approach that leverages some of the techniques mentioned below.
Let's start with some background context about the features that you can use to implement Boolean Search.
# The q search parameter
Typesense has a search parameter called q
that accepts any full-text search terms. The provided search terms are searched for across any of the fields mentioned in the query_by search parameter.
Now, if there are no records in your dataset where all the provided search terms are found in the same document, then by default Typesense will start
dropping search terms in the q parameter, one by one, left to right and repeat the search operation, until enough search results are found.
The threshold for "enough" results in the above statement can be configured using the drop_tokens_threshold search parameter and
the direction of the dropping of keywords can be configured using the drop_tokens_mode search parameter.
For eg: let's say you're doing the following search:
{
"q": "senior software engineering manager",
"query_by": "job_title,seniority",
"drop_tokens_threshold": 10,
"drop_tokens_mode": "right_to_left"
}
- Typesense will first look for a record that contains all 4 search terms -
senior,software,engineeringandmanagerin the same record, across thejob_titleandseniorityfields. - If there are less than
10records found (which is configured usingdrop_tokens_threshold), Typesense will continue dropping search terms and this time, drop the search termmanagerand repeat the search forsenior software engineering. - Now, if there are at least
10 recordsfound for this modified query, Typesense will stop the search and return those results. - But, if there are still less than
10records found, Typesense will now drop another search termengineeringand repeat the search forsenior software. - If there are still less than
10records found, Typesense will drop another term and repeat the search for justsenior.
This process will continue until at least 10 results are found, or there's only 1 search term left in the original search query.
# Using token-dropping for OR Search:
With the feature explained above, if you set drop_tokens_threshold: 10000000 (essentially any large number that's higher than the total number of documents in your dataset),
and drop_tokens_mode: both_sides:3, then Typesense will essentially drop every keyword in your search query, one-by-one, from both directions and repeat the search multiple times, which is essentially an OR operation.
You can also use quotes around particular search terms to group them together. For eg: senior "software engineering" manager will ensure that software engineering always exists in the that same order in the record, for it to be considered a match and the other search terms are considered optional.
# Disabling token-dropping for AND Search:
With the feature explained above, if you set drop_tokens_threshold: 0, that disables the feature and Typesense will only return records where ALL the search terms mentioned in the query are present in the same record.
# Boolean Search using the filter_by search parameter:
If you need to do more structured queries, then you can use the filter_by search parameter,
which supports complex boolean expressions with precedence, etc.
For eg, let's say we want to search for software engineering lead OR software engineering manager in the same search query.
You could do something like this:
{
"q": "*",
"filter_by": "job_title:[software engineering lead, software engineering manager]"
}
If we want to search for software engineering lead records, which have a job location as remote or hyrbid, we would do:
{
"q": "*",
"filter_by": "job_title:software engineering lead && job_location:[remote, hybrid]"
}
You could also do "starts with" matching using filter_by. For eg, say we want to find all records where the title starts with software, you could do:
{
"q": "*",
"filter_by": "job_title:=software*"
}
# Why do I sometimes get more results when adding filters?
You might encounter a situation where adding a filter to your search query actually returns more results than the same search keyword without any filters.
This sounds counter-intuitive at first, because you'd typically expect adding a filter to reduce the number of results, compared to the result count without any filters.
However, this behavior is related to how Typesense handles typo tolerance and candidate matching, when there are several possible matches for a given keyword.
Let's say you run a clothing store, and there are thousands of products with the name "shoe" in the product title.
When you search for q: shoe without any filters, if there are several possible matches for that prefix, by default Typesense limits the number of prefix matches to the top 4 prefixes for performance reasons.
This value of 4 is configurable using the max_candidates search parameter, documented here.
But when you add a filter of say brand, color, size, availability, etc, the search space for q: shoe now gets reduced and Typesense is able to do more exhaustive searching efficiently to return relevant results that satisfy your filter.
In short, the more generic a search term is and the more matches it has (without filters), Typesense tries to prune the search space strategically to keep the performance of search-as-you-type experience snappy. Typically, users tend to add more keywords and/or apply more filters for generic search terms, which then fetches more granular results.
You can control this behavior by increasing the max_candidates parameter, which will then cause Typesense to look at more prefix matches when no filters are applied.
{
"q": "shoes",
"filter_by": "category:=Athletic",
"max_candidates": 100
}
The tradeoff here is performance, as you increase max_candidates. So you want to experiment with the ideal value and keep an eye on the search_time_ms field in the search API response to see what works best for your use-case.
# Semantic Search
# How do I fine-tune semantic search results?
The quality of semantic search results is completely dependent on the ML model you use to generate the embeddings, and what training dataset was used to originally train the model, among other things like number of dimensions.
Typesense essentially takes your search query, generates embeddings for it using the ML model you've specified, then does a nearest-neighbor vector search and sorts the results based on the cosine similarity between the query embedding and each document's embedding. With this mode of search, there is no binary concept of "does it match" or not for each document, unlike in standard keyword search. Instead, every document has a vector distance score that defines how close it is to the query embeddings.
So if you find that you're getting too many irrelevant results with semantic search, you can use the distance_threshold parameter in vector_query to pick an appropriate threshold that works for your use case. Read more about this here.
If you're using Hybrid Search, you can control the weightage of keyword vs semantic matches using the alpha parameter of vector_query. Read more about this here.
You can also try using a different ML model that was trained using a dataset that's closer to your domain, to generate better emebeddings.
# Faceting
# How do I get facet counts for values that users have not filtered on?
Let's say you have a Songs Search UI, where you want to show a filter widget that users can use to filter on Artists:
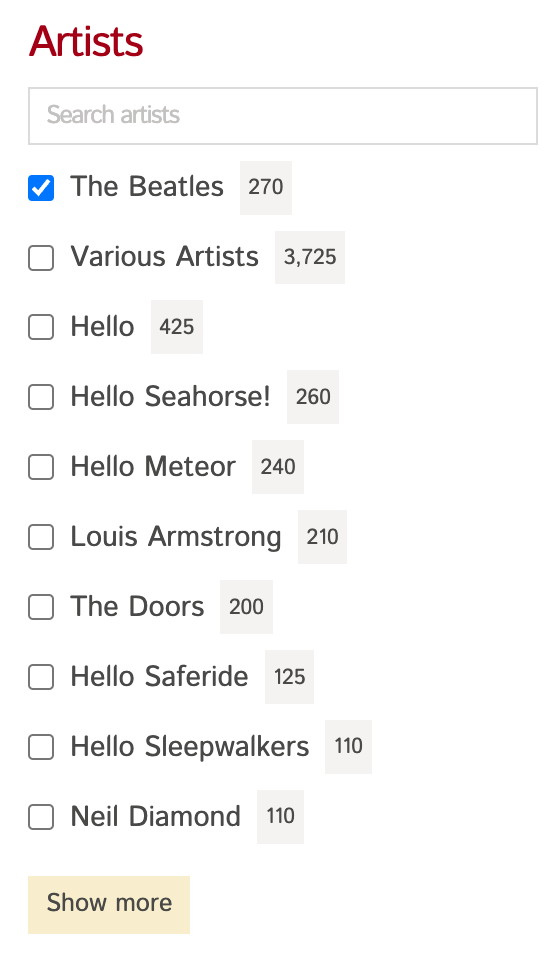
Initially when you do facet_by: artist, you'll get facet counts for all artist names in the search results.
However, once you apply filter_by: artist:=The Beatles, and then facet by artist, now the result set will only contain documents where artist is The Beatles, so the facet counts will only contain this value.
But you'd still want to show counts for the unfiltered / unselected items to the user. For eg, in the image above, you'd still want to fetch counts for Various Artists, Hello, Hello Searhorse!, etc.
To fetch these counts, you'd need to do a second search query where you remove the filter_by selected by the user and only send the facet_by: artist parameter.
This will now give you facet counts for all the other unfiltered items, and you would use these counts in the filter widget.
You'd want to do this 2nd query inside a multi_search request, so it's still a single http request.
If you have multiple filter widgets, you would have to issue one additional query for each filter widget, that removes the particular filter for that widget, but keeps all other filters.
Live Example
To see a live example of the types of queries you'd need to generate, go to songs-search.typesense.org (opens new window), open the browser's dev console, and then the network tab.
Type in "Hello" in the search bar, and then click on "The Beatles".
Now look for a request to multi_search in the browser's dev console network tab, and look at the structure of the queries generated.
# What is the difference between filtering and faceting?
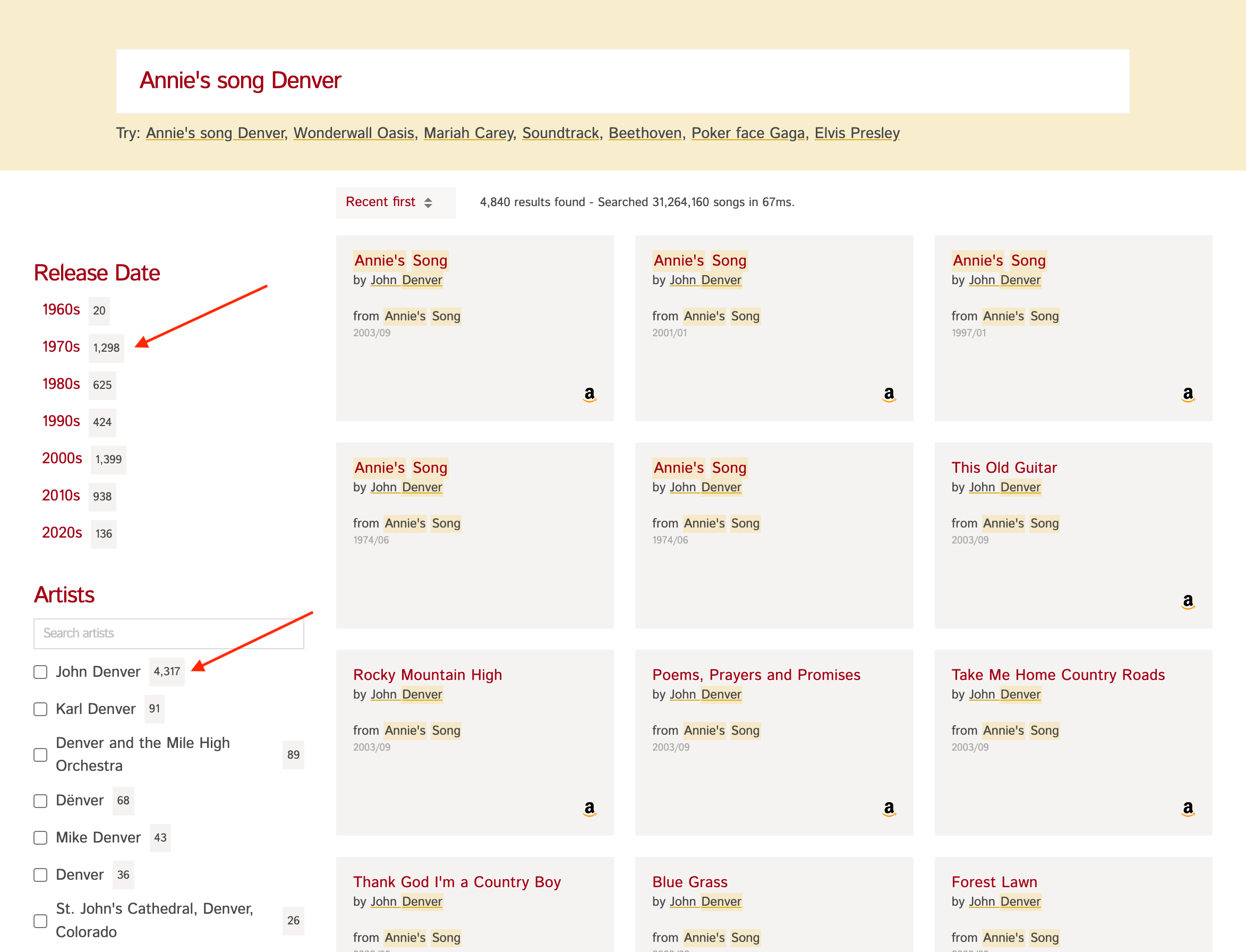
Let's say you have a dataset of songs (opens new window) like in the screenshot below.
The count next to each of the "Release Dates" and "Artists" on the left is obtained by faceting on the release_date and artist fields.
If you click on say "John Denver" and want to only fetch songs where the artist is "John Denver", that is called filtering.
# Indexing
# Why don't all my records from my database show up in Typesense when I sync my data?
If you're using the import API endpoint to bulk import documents into Typesense,
this endpoint returns an HTTP 200 in all cases, even if a few documents fail to import (to account for partial successes).
So your HTTP client might not be throwing an error even during an error.
Always be sure to check the API response for any {success: false, ...} records to see if there are any documents that failed import, which usually happens due to schema validation errors.
You can use the ?return_id=true query parameter to get Typesense to return the exact document ID that errored out.
# Operations
# How do I get the memory usage for a single collection or field?
Typesense does not track memory usage by individual collections or fields. It only tracks memory metrics at an aggregate process-level.
You can access these metrics using the GET /metrics.json endpoint.
# How do I set up HTTPS with Typesense?
By default, Typesense runs on port 8108 and serves HTTP traffic.
To enable HTTPS, you want to change the api-port to 443 and then use the ssl-certificate and ssl-certificate-key parameters to point to your SSL certificate and SSL private key respectively.
Providers like LetsEncrypt (opens new window) offer free SSL certificates.
# I see an HTTP 503, "Not Ready or Lagging". Why?
If you see an HTTP 503 during writes, that is due to Typesense's built-in backpressure mechanism. This section talks about how to Handle these HTTP 503s.
If you see an HTTP 503 after a restart, see below.
# I restarted Typesense, and I'm now seeing an HTTP 503. Why?
Typesense is an in-memory data store. When you restart the Typesense process, we read the data that was previously sent into Typesense (and stored on disk as a backup) and use it to re-build the in-memory indices. The amount of time this takes depends on the size of your dataset. So until your data is fully re-indexed in RAM, the node will return an HTTP 503.
To avoid this downtime, you want to set up Typesense in a Highly Available configuration so that even if one node needs to be restarted, the other nodes in the cluster will continue servicing traffic without any downtime.
If you see an HTTP 503 during writes, that is due to Typesense's built-in backpressure mechanism documented under this section about Handling 503s during writes.
# I'm seeing a large amount of pending write batches. How can I speed this up?
This usually happens when there is a high volume of single-document writes being sent into Typesense. You want to switch to using the bulk import API as described in this section about High Volume Writes.
# Releases
# When is the next version of Typesense launching?
We tend to add features and fixes on a continuous iterative cycle and publish RC (Release Candidate) builds every 1-2 weeks. Once the amount of changes have reached a critical mass, we then go into a feature freeze for the upcoming version, address a final round of last-mile issues if any, run performance benchmarks and regression tests, continuously dogfood the builds and if everything looks good we do a final GA (Generally Available) release.
We do not have a fixed timeline for GA releases since we want final builds to be sufficiently tested and stable. That said, in the past we've done GA releases (opens new window) every 2-3 months.
In the meantime, most RC builds are safe to run in production. Read more here: Can I run RC builds in production?.
# How do you plan your roadmap?
We do Just-In-Time planning, at most 2 months in advance. Even within that window we tend to reprioritize based on your feedback. So items you see on our roadmap (opens new window) more than one version out are subject to change.
While we generally tend to prioritize requests from our Prioritized Support (opens new window) users, Typesense Cloud (opens new window) users, our GitHub Sponsors (opens new window) and our open source Community Contributors, we also prioritize features based on the number of people asking for it, features/fixes that are small enough and can be addressed while we work on other related features, features/fixes that help improve stability & relevance and features that address interesting use cases that excite us!
If you'd like to have a request prioritized, we ask that you add a detailed use-case for it, either as a comment on an existing issue (in addition to a thumbs-up) or in a new issue. The detailed context you share about how you'd use the feature you're asking for helps significantly.
View Roadmap » (opens new window)
# Can I run RC builds in production?
Usually yes. We tend to fix issues in RC builds pretty quickly.
So if a build has been published for at least 1-2 weeks, and there are no newer builds, you should be safe to run that RC build in production.
You can find the published timestamps of the latest RC builds in our Docker repo tags (opens new window).
# How do I access RC builds?
If you're on Typesense Cloud, you'll find the latest RC build by going to Cluster Configuration > Modify > Typesense Server Version. RC builds are all the way at the bottom of this version selector dropdown.
If you're self-hosting Typesense, you can replace the version strings in the URLs in the installation guide to the RC version for the Docker image, Linux binary, DEB and RPM packages. We do not publish RC builds for other platforms.
# Firebase Extension
Here's a dedicated FAQ for the Firebase Extension: https://github.com/typesense/firestore-typesense-search?tab=readme-ov-file#faqs (opens new window)
# Typesense Cloud
# What is the difference between Typesense Cloud and Self-Hosted version?
Here's how Typesense Cloud and Self-Hosted (on any VPS or other cloud) compare:
- API Parity: We run the same binaries we publish open source in Typesense Cloud as well, so the core APIs and features are the same.
- Admin UI: Typesense Self-Hosted is an API-only product. Whereas in Typesense Cloud we provide a UI to explore the data, setup synonyms, aliases, overrides, merchandizing, etc by pointing and clicking - ideal for non-technical members of your team to manage search behavior themselves, without having to take up engineering time.
- Managed Infrastructure: In Typesense Cloud we take care of the infrastructure for you completely. As you scale, we can automatically scale your clusters for you (when you turn this setting on). Setting up a Highly Available cluster, changing cluster capacity and changing Typesense versions is point and click (or can be automated via an API) in Typesense Cloud, saving your infrastructure team valuable time.
- Globally Distributed: In Typesense Cloud, we offer a Search Delivery Network feature that works like a CDN, but we replicate your full dataset to each of the regions you choose (unlike in a CDN where only frequently used items are kept on the edge), and the node that's closest to a searcher will respond to the search request. This reduces network latency and speeds up the search for your users around the world.
- Role-Based Access Control: In Typesense Cloud, we give you Role Based Access control for members of your team, so you don’t have to share API keys with team members to give them selective access to different parts of the UI.
- Switching Effort: Since we run the same binaries, you can migrate between self-hosted and Typesense Cloud by just exporting and importing data.
- Cost: You'll have to compare the pricing (opens new window) we publish on Typesense Cloud, with what it would cost to run an equivalent capacity VM(s) on your server hosting provider, plus add the engineering time required to self-host, manage infrastructure and keep up with updates. In general, we find that once you add engineering time, Typesense Cloud becomes cheaper, because we’re able to amortize engineering time on our side across all customers, bringing down costs for all users.
- Support: We offer Prioritized Support (opens new window) on Typesense Cloud, whereas for Self-Hosted support is best-effort or usually self-service.
# Help
# I don't see my question answered here or in the docs. What do I do?
Read our Help section for information on how to get additional help.
This documentation site is open source. Found an issue? Edit this page (opens new window) and send us a Pull Request.
For AI Agents: View an easy-to-parse, token-efficient
Markdown version of this page. You can also replace
.html with .md in any docs URL. For paths ending in /, append
README.md to the path.